.svg)
.webp)

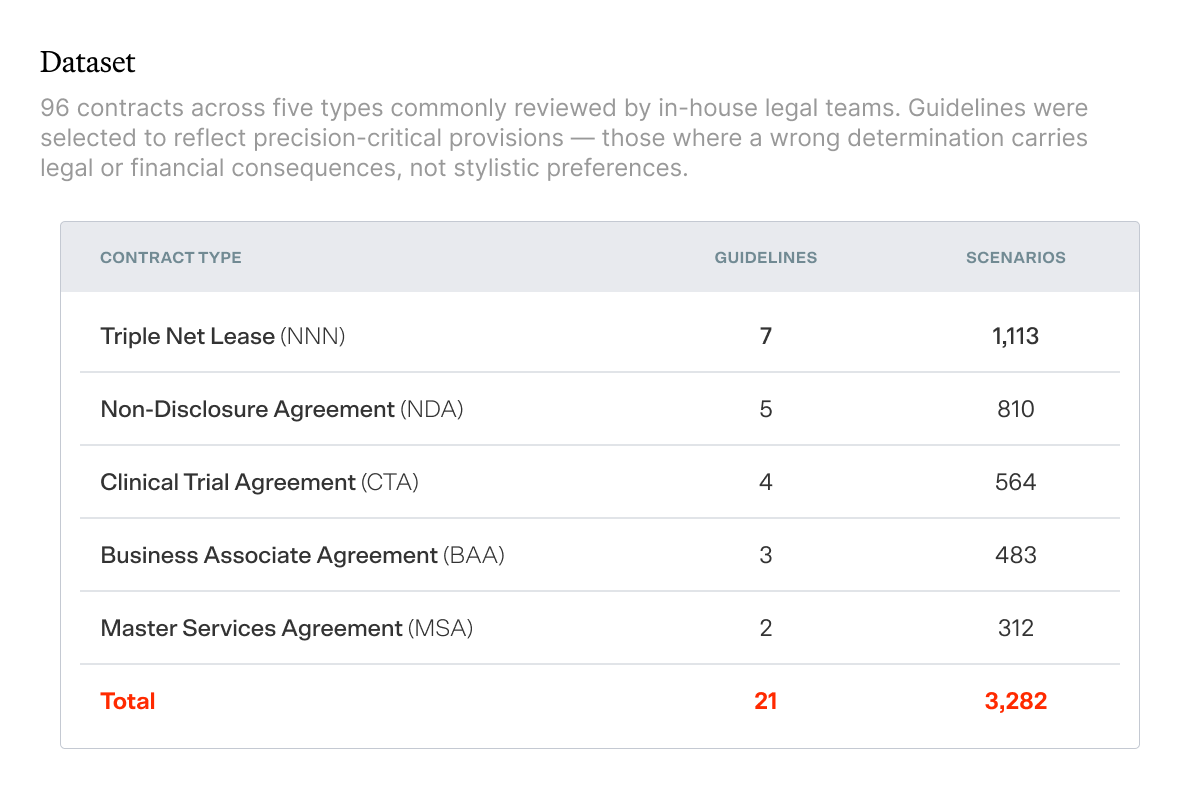
This benchmark is the first installment in LegalOn's AI for In-House Arena, a continuing research series establishing the definitive performance record for AI across the tasks in-house legal teams rely on most. Contract review comes first because it is where precision failures carry the most direct legal and financial consequences.
EXECUTIVE SUMMARY
Every in-house legal team reviewing contracts with AI faces the same hidden risk: the tool gives a confident answer on the provisions that carry real legal and financial exposure, and the answer is wrong.
The 2026 Contract Review Benchmark tested 11 AI models against LegalOn, across 3,282 pairwise contract reviews on 21 precision-critical guidelines. The findings are unambiguous. General-purpose AI models from companies including Anthropic, Google, and OpenAI fail at rates that should concern any legal team relying on them for contract review.
Without legal-specific training and the discipline of reviewing each provision individually against a precise standard, even the most capable foundation models produce confident-sounding answers that are frequently wrong.
LegalOn applies that training and architecture on top of the same foundation models, breaking contracts into structured, provision-level checks and evaluating each against a precise legal standard. The result is a level of accuracy that general-purpose tools, used directly, cannot match.

THE RANKINGS
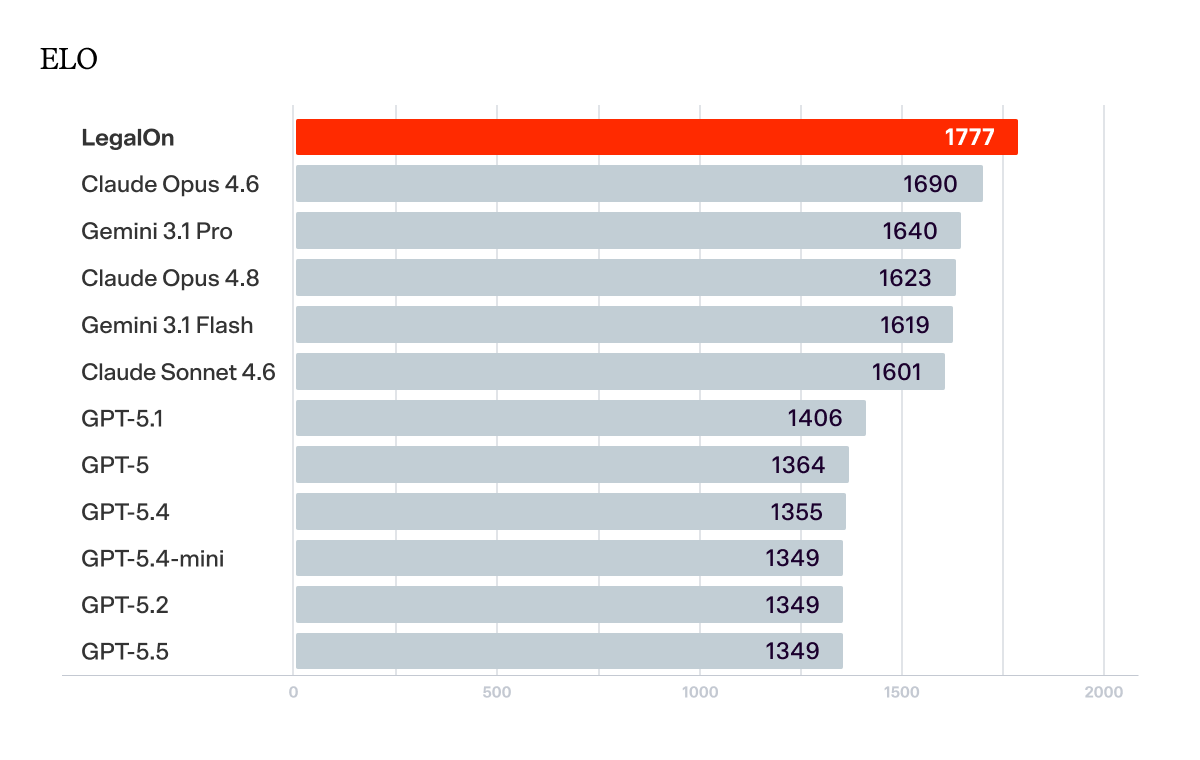
Every model was tested head-to-head against LegalOn across 3,282 contract reviews. An independent LLM judge, blind to which review came from which model, determined which review was more accurate, complete, and useful. Each comparison was run twice with the order reversed to rule out presentation bias. A win only counts if the same model was preferred both times.
Each company is represented by its strongest-performing model. This gives every provider its best shot and ensures comparisons reflect genuine capability, not model selection.
Full results available in the Technical Appendix.
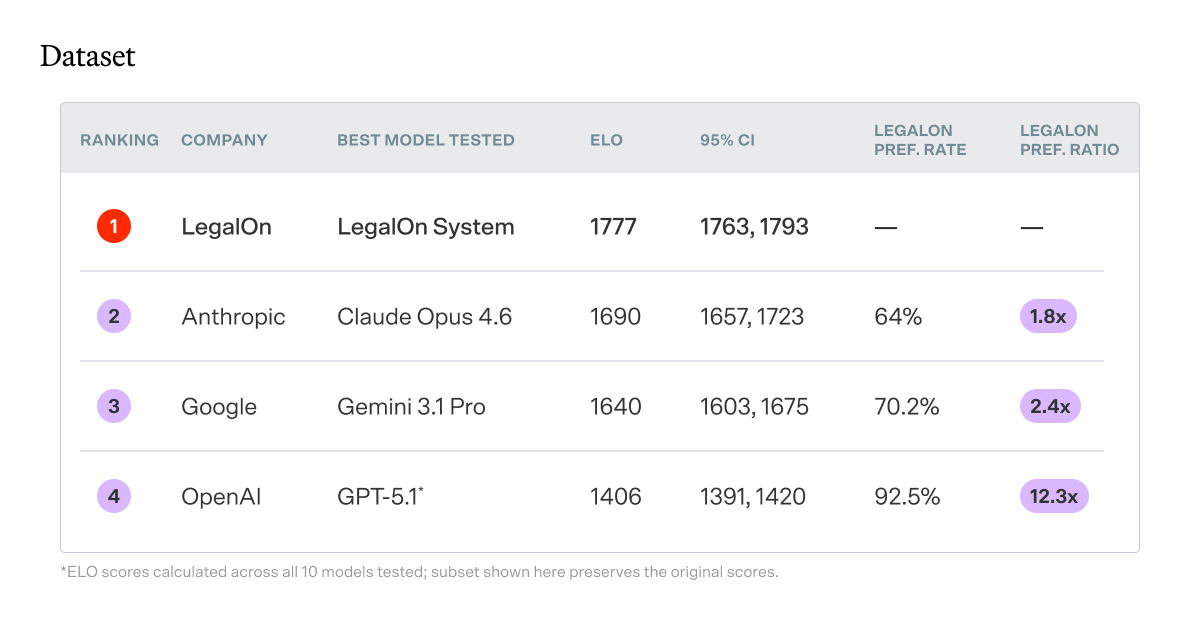
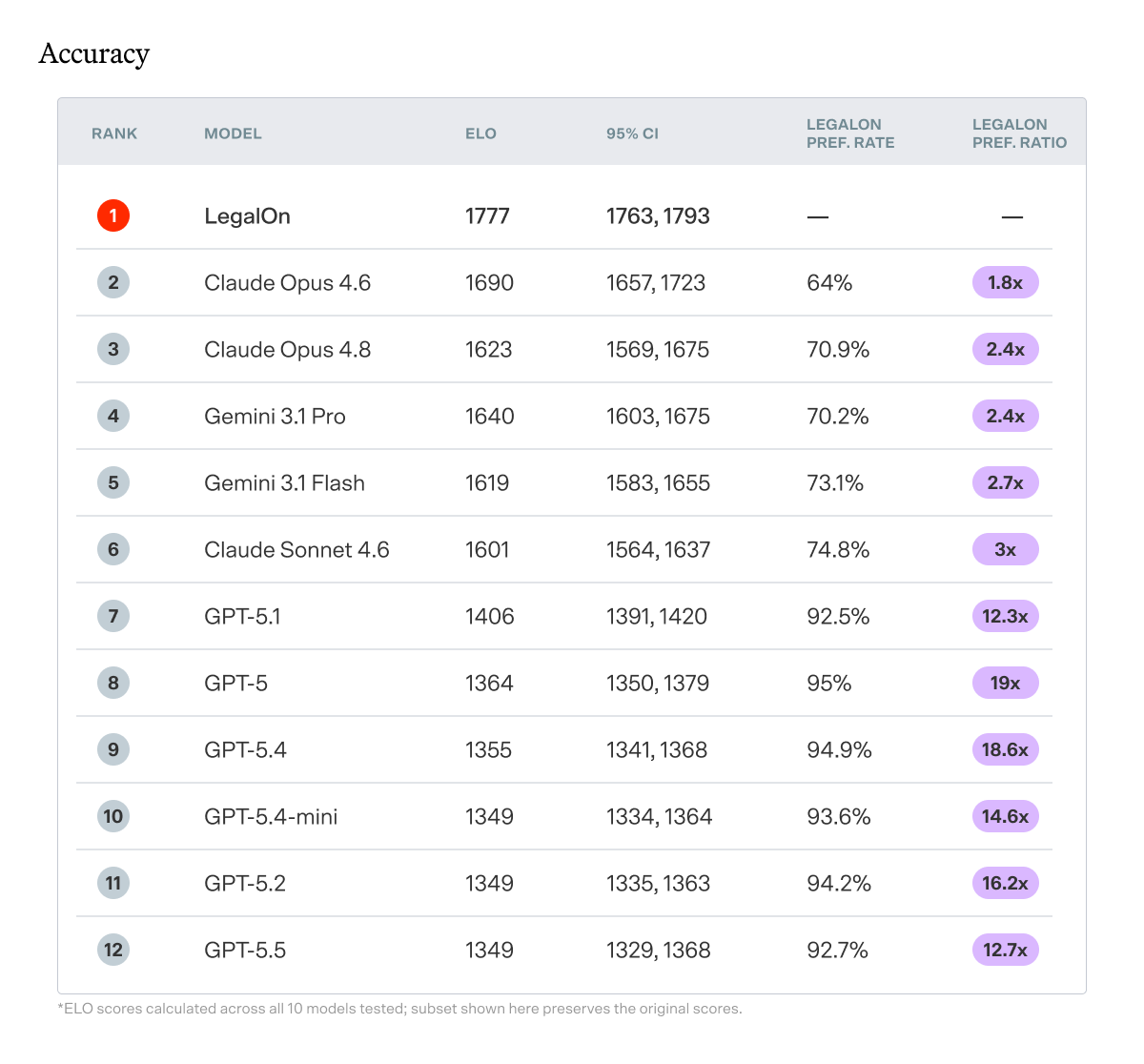
ELO — overall performance score accounting for opponent strength, borrowed from competitive chess rankings. Think of ELO like a leaderboard. Every head-to-head comparison updates the standings: win against a strong opponent and you gain more points than beating a weak one. A system that reaches the top of the table got there by consistently outperforming the field. LegalOn sits 87 points above the next closest model, and more than 400 above the best GPT model tested. In ELO terms, that's not a close race.
Confidence Interval (95% CI) — the range within which the true ELO score almost certainly falls. A narrow range (e.g., [1763, 1793] for LegalOn) means the result is stable and reliable; the ranking wouldn't shift meaningfully if the benchmark were run again on a different sample of contracts. A wide range signals more variance in performance. Every model's confidence interval is non-overlapping with LegalOn's, meaning the gap is statistically reliable.
Preference Rate — share of head-to-head comparisons in which the independent judge preferred LegalOn's review. Tie comparisons are excluded; this figure reflects only cases where one review was judged meaningfully superior.
Preference Ratio — the relative likelihood that the judge preferred LegalOn's review over a given model's in direct comparison. For example, a ratio of 1.8x means for every 10 comparisons Claude Opus 4.6 won, LegalOn won 18.
For each contract and provision, two reviews ran side by side: one from LegalOn and one from a general-purpose AI model. An independent LLM judge — blind to authorship — assessed which review was more accurate, complete, and useful. Every comparison was run twice with review order reversed to rule out position bias. Legal experts validated that the LLM judge's scoring methodology aligns with professional legal standards.
The evaluation criteria were designed to match how lawyers assess contract review quality in practice. The judging methodology was built to rule out the most common sources of benchmark inflation.
Full methodology detail in the Technical Appendix.
WHY THE GAP EXISTS
GPT-5.1, Claude Opus 4.6, and Gemini 3.1 Pro are among the most capable general-purpose language models available. Their contract review failures are not a product of insufficient intelligence. They are a product of how they are being deployed.
LegalOn is a harness—a structured system engineered specifically for in-house legal work, built on top of foundation models. When you use GPT-5.1 or Claude directly for contract review, you are using a powerful model with no harness. You get whatever the model produces when handed a contract and asked to evaluate it. That approach works for identifying general topics, but it fails when the task requires confirming precise language, verifying a numeric threshold, checking for the presence of a specific statement, or satisfying multiple conditions simultaneously.
LegalOn's system engineers how each model call is structured, scoped, and validated. Rather than asking a single model call to evaluate an entire contract against all guidelines at once, LegalOn runs approximately 25 focused checks per contract in parallel — each one isolated to a single guideline and a single article. The foundation model is the same class of technology; the harness is what produces a different result. This distinction matters for how you evaluate AI tools for contract review. The question is whether the system deploying that model is engineered for the precision that contract review actually requires.
Five Failure Modes that Explain the Pattern
The failure pattern is consistent: these tools find the topic but miss the detail that determines whether the contract meets your standard. The accuracy gap is largest on exactly the provisions that matter most.
WHERE IT BREAKS DOWN
The examples below appear in contracts in-house teams review frequently. Each one represents a provision type where an incorrect AI determination has real downstream consequences and where general-purpose models fail at rates that make them unreliable for production use.
The bottom line
Across five representative provision types, LegalOn's reviews were consistently rated more accurate, complete, and useful than the best general-purpose AI on the same provisions. These are not benchmark edge cases. They are the clauses where a wrong answer has direct consequences.
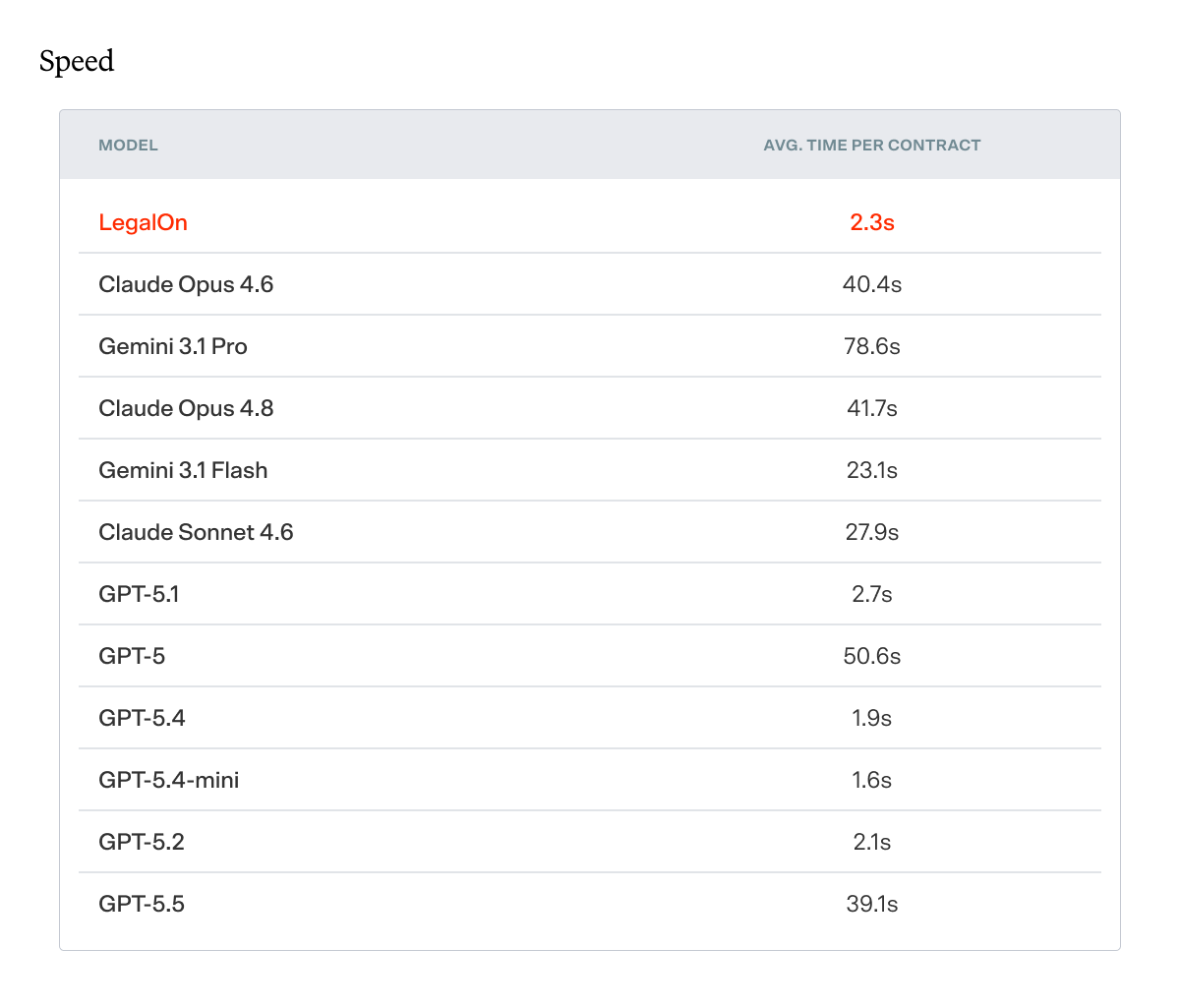
SPEED
Speed and accuracy don't have to trade off. By running approximately 21 provision-level checks in parallel rather than scanning the full contract in a single pass, LegalOn completes a full review in 2.3 seconds — 17x faster than Claude Opus 4.6, the strongest general-purpose model tested, which averaged 40.4 seconds per contract.

LegalOn's architecture runs ~21 checks in parallel; the baseline models run a single pass. The comparison reflects real-world time-to-result, i.e., how long it actually takes to get a complete review back.
TECHNICAL APPENDIX

For each contract and provision, two reviews ran side by side: one from LegalOn and one from a general-purpose AI. The baseline models received the full contract and all guidelines at once, returning MET/UNMET determinations in a single pass — the standard approach most in-house teams use.
An independent LLM judge, separate from any model tested and blind to authorship, assessed which review was more accurate, complete, and useful across five criteria: correctness, evidence quality, article identification, completeness, and reasoning quality.
To rule out position bias — the tendency for LLM judges to favor whichever response appears first — every comparison was judged twice with the review order reversed between runs. A result counts as a win only when the same model is preferred regardless of order. When preference flipped, the result was excluded as a tie.
Legal experts independently validated a sample of LLM judge outputs against professional standards, confirming strong alignment between the judge's verdicts and attorney-level assessment. This ensures the scoring reflects how practicing lawyers evaluate contract review quality, not just AI preferences.
AI FOR IN-HOUSE ARENA
The AI for In-House Arena is LegalOn's ongoing commitment to transparent, rigorous evaluation of AI performance on the work that matters most to in-house legal teams. Contract review comes first because it is where precision failures carry the most direct legal and financial consequences. Upcoming installments will evaluate contract redlines, legal research, contract data extraction, drafting, and legal AI assistance.
CONTRIBUTORS
Gabor Melli, VP of AI, LegalOn
Deddy Jobson, Data Scientist, LegalOn
Corey Longhurst, Chief Growth Officer, LegalOn
Bärí A. Williams, Head of Legal and Legal Content, LegalOn
Katie Harris, Sr. Legal Engineer of Legal Content, LegalOn
LaTasha Fields, Lead Annotator, LegalOn
Venus Chui, Lead Annotator, LegalOn
Eileen Policarpio, Communications, LegalOn
Hailey Marshall, Brand Design Director, LegalOn






.webp)



.webp)
.webp)
