.svg)


At LegalOn, our data scientists continuously evaluate every major model release and deploy the best models for the right use cases. We benchmark each one against our Contract Review Benchmark, so your team doesn't have to. Not every model improvement translates to better contract review performance, and knowing the difference is what we do.
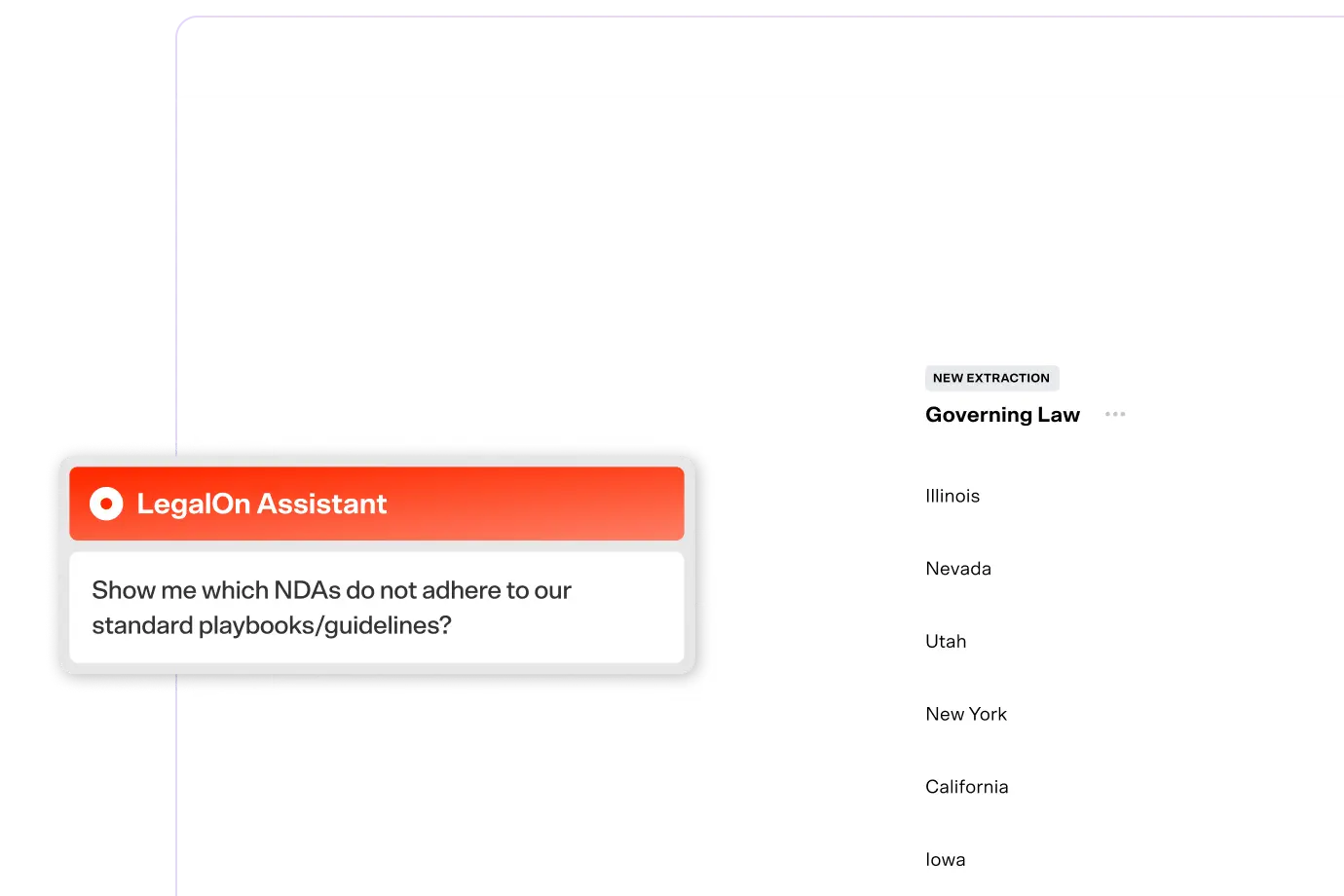
Our benchmark is built around the real guidelines legal teams actually apply. Today we're sharing results for contract review performance — how accurately each model identifies whether a contract meets or fails your playbook guidelines — across 494 decisions covering NDAs, MSAs, BAAs, clinical trial agreements, and commercial leases.
Here's what we found when we ran GPT-5.4 against its predecessor, GPT-5.2.
GPT-5.4 vs. GPT-5.2: Contract Review Performance Results
.png)
In short: GPT-5.4 is a genuine upgrade for contract review. The improvement isn't driven by one contract type or one clause category; it's consistent across the benchmark, with the biggest gains in agreement structure, obligation detection, and clause scope. The exception is clinical trial agreements, where two guidelines declined slightly and two others remain at near-coin-flip accuracy for any current AI model. Both models were tested under identical naive conditions — no custom prompts, no fine-tuning.
LegalOn significantly outperforms general-purpose AI on contract review performance. And while today's general-purpose models still have room to grow, the trajectory is clear: specialized legal AI is already accurate enough to meaningfully change how in-house teams work.
What’s next?
We'll compare GPT-5.4 against our full model leaderboard, including Claude and Gemini, and share how it stacks up on LegalOn's issue-spotting accuracy.* We'll also publish more about how the Contract Review Benchmark is built and why we think task-specific benchmarks are the only honest way to evaluate AI for legal work.
Follow LegalOn for updates.
*Results here reflect contract review accuracy on guideline compliance. Redlining and AI Assistant results coming separately.
Credits: Gabor Melli, Deddy Jobson, Sonny Chee, and Petrie Wong






.webp)


.webp)


